背景
上周更新了一篇文章《一致性Hash算法与虚拟节点》,阅读和收藏人数挺多的。
今天有朋友问了我一个问题,虚拟节点如何保证均匀分布?
我不假思索的回答,
不需要保证虚拟节点的均匀分布,
虚拟节点用以保证相对的均匀靠得是量变产生质变,
就像我文末提到的,在实际场景中,虚拟节点的个数只有3个是远远不够的。
例如Dubbo中用到一致性hash算法时,默认的虚拟节点个数是160个,
假设我们有四个服务节点需要创建虚拟节点,那就会有 4 * 160 = 640 个虚拟节点,
在这样大量的基数下,必然他们的分布就会呈一种相对均匀的状态。

回答完我感觉很满意,不愧是我!
可转念一想,再想,三想,
好像不是这么一回事,
别说是有640个节点了,就算有6400个,64000个节点又如何呢?
在极小极小的概率下,如果hash算法不能保证映射的均匀性,
他们依然可能落在十分聚集的一小块区域中。
反推一下,既然一致性hash算法作为一个成熟并拥有很多应用场景的算法,
不可能如此不严谨,所以hash算法本身应该是可以保证映射的一致性的。
“应该”?这么不确定可不行,我得好好补补空白,确实之前没有去了解过hash算法到底实现了个啥。

东查西查,终于有了答案。
百度百科对Hash的名次解释如下:
Hash,一般翻译做散列、杂凑,或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。
哦,原来就是散列函数啊!
那就简单了,散列函数我本科学过啊!
脑海一番搜索,糟糕,我真的学过吗?唯一的印象就是学过。

没事,学过忘了没关系,再学就完事了。
以下是干货,
一个合格的散列函数包含三个特征:
- 单向性:容易计算输入的散列结果,但是从散列结果无法倒推出输入;
- 抗冲突性:很难找到两个不同的输入散列结果相同;
- 映射分布均匀性和差分分布均匀性:散列结果中 bit 位上的 0 和 1 的数量应当大致相等;改变输入内容的 1 个 bit 信息会导致散列结果一半以上的 bit 位变化(雪崩效应)。
真刺激,到这是不是就完事了,散列函数保证了映射的分布均匀性。
我劝你要不要再回去看两遍映射分布均匀性和差分分布均匀性的内容。

看完了吗?
再想想《一致性Hash算法与虚拟节点》中的hash环,
有没有顿时反应过来,这边又TM不严谨了。

说好的散列结果中bit位上 0 和 1 的数量大致相等,这要是映射到hash环上,
最小值岂不是 00000000000000001111111111111111,
最大值岂不是 11111111111111110000000000000000,
(别数数字,我随便打的,你懂我意思吧)
那在hash环上不就出现了一段真空地带了吗?
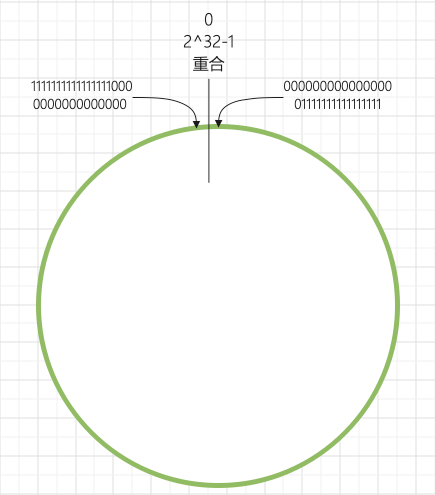
虽然实际上真空地带比图上的还小,只有 65536/4294967295 约等于 百万分之十五,
但这微小的缺口无疑将带来无法估计的灾难,尤其是在实际生产环境中,
你永远不知道一个微小的漏洞可能会造成多大的后果。

不行,“革命还未成功,同志仍需努力。”
我应该离胜利不远了,
正好,最近在学Dubbo,
里面的负载均衡就用到了一致性hash算法,
我直接掏出源码看看不就知道了。
Dubbo仓库地址:https://github.com/apache/dubbo
找到 ConsistentHashLoadBalance 类,
这边我将我们最关心的代码贴上来,
| |
其中 replicaNumber 就是我们要创建的虚拟节点数目(副本数),
可以看到,代码中巧妙的通过两层 for 循环,
令外层循环上限除以 4,内层循环 4 次,使得总副本数目保持原水平,
如 (160/4)* 4 = 160。
为什么要有这种安排呢?
让我们继续往下看,
首先让实际服务地址加上 i 形成新的字符串,再对其取 MD5 值,
也就是说一个 MD5 值实际上是要生成 4 个副本位置的。
问题一个接着一个,
为什么要让一个 MD5 值生成 4 个副本位置?
一来节约了计算的成本,
二来实际上一个 MD5 值确实够生成 4 个副本位置了。
别忘了,我们的 hash 环只有 2 的 32 次方 - 1 个位置,
而一个 MD5 值却有 16 个字节,16 * 8 = 128 个bit,
这意味着只要我们切分得当,一个 MD5 值确实可以生成 4 个hash环中的位置值。
让我们继续看看上面贴出来的代码中的 hash 方法实现
| |
我来演示一下第一个副本位置值的生成过程,
假设我们的address是 127.0.0.1:20880,i 为0。
那么此时我们的 digest 就是 127.0.0.1:208800 取 MD5值,其 16 进制为
| |
在 byte 数组中为(展示二进制)
| |
分解上面那个略微复杂但有规律可循的 hash 方法,
首先计算
| |
此刻,number为0,
即原式变为
| |
结果为
| |
依次计算
| |
结果分别为
| |
进行 或运算,结果为
| |
再与 0xFFFFFFFFL 进行 与运算,保证结果为 32 位。
到这里,我们的第一个副本位置终于确定啦
| |
你可以依葫芦画瓢的由同一个 MD5 值生成另外三个副本位置,
我将另外三个副本位置附上,你可以像上数学课时一样,
当作参考答案,确保自己的思路是正确的。
另外三个副本位置如下:
| |
总结
撒花,终于算完了,我们可以来总结一下了。

在Dubbo的源码中,
我们发现,实现一致性hash算法时,
用于计算副本位置的定位算法,实际上每个位置只需要 MD5 值的 四分之一,
而上面提到的合格的散列函数应该(大致)包含一半bit为 0 一半为 1 大于 四分之一,
所以定位算法产生的结果覆盖了 0 ~ (2 的 32 次方 -1),
即 hash 环上所有位置,
又因为散列函数的雪崩效应,实现了映射分布的均匀性,
即虚拟节点的均匀分布。

怎么样?同学,对我这个答案还满意吗?
所以说,同一个问题,
或许我们可以“不假思索”的回答,
但有时候我们也可以沉下心来好好研究研究。